文字コードとは?初心者にもわかる仕組みと文字化けの原因
パソコンやスマートフォンで文字を扱うとき、見えないところで使われているのが「文字コード」です。 文字コードを正しく理解していないと、「文字化け」や「全角・半角の混在」などのトラブルを引き起こす原因になります。 本記事では、文字コードの基本から、主な種類、文字化けの正体、全角・半角との関係までをわかりやすく解説します。
文字コードとは何か
コンピュータは文字をそのまま理解できません。「0」と「1」の組み合わせで記憶したり計算したりします。 そのため、文字は「数字」に変換して扱います。 この「文字と数字の対応表」のことを「文字コード」と呼びます。
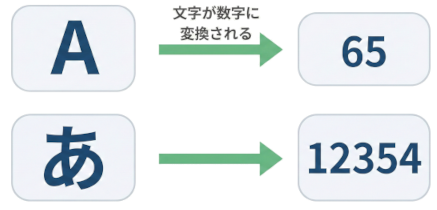
65、日本語の「あ」は 12354 として保存されます。
なぜ文字コードが必要なのか
コンピュータは0と1のデジタル信号しか理解できません。 そのため、「A」「あ」「@」といった文字も、内部では「数値」に変換されて保存されます。 どの文字をどの数字に割り当てるかを決めているのが文字コードです。
世界中で文字が使われるようになると、言語ごとに異なる文字コードが登場しました。 英語中心の「ASCII」、日本語を扱う「Shift_JIS」、世界共通の「UTF-8」などが代表例です。
主な文字コードの種類と特徴
| 文字コード | 対応言語 | 特徴 | 現在の利用状況 |
|---|---|---|---|
| ASCII | 英語 | 最も基本的。英数字と記号のみ。 | 英語や数字のみを扱う場合に使用 |
| Shift_JIS | 英語/日本語 | 英語は1バイト、日本語は2バイト構造。Windowsで長く使われた。 | 一部の業務システムで使用中 |
| UTF-8 | 全言語 | 世界標準。Webやスマホアプリで主流。 | 2025年現在の主流 |
文字化けはなぜ起きるのか
文字化けとは、「文字コードが一致していない状態」で起こります。 たとえば、UTF-8で保存したファイルをShift_JISとして開くと、数字の割り当てがズレて別の文字に見えてしまいます。
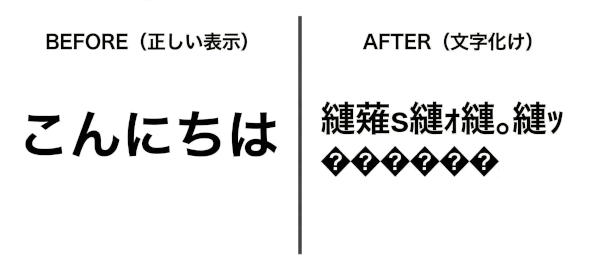
こんな経験ありませんか?文字化けが起きる主な原因
文字化けは、特に以下のような場面で発生しやすくなります。
- メールの送受信: 送信側と受信側でメールソフトの文字コード設定が違うと、件名や本文が文字化けします。
- CSVファイルを開くとき: UTF-8で作成されたCSVファイルを、Shift_JISを標準とする古いExcelで直接開くと、特に人名や住所の列が文字化けすることがあります。
- Webサイトのフォーム: Webページ(UTF-8)から入力されたデータを、古いシステム(Shift_JIS)で処理しようとすると、データが文字化けして登録されることがあります。
これらはすべて、扱うデータの「文字コード」と、それを受け取って表示・処理する側の「文字コード」が一致しないために発生する問題です。
文字コードを確認・変換する方法
- テキストエディタで「文字コード設定」を確認(UTF-8推奨)
- ファイルを保存するときに、文字コードを指定する
まとめ
文字コードは、すべての文字データの基礎となる仕組みです。 文字化けも全角・半角の違いも、その裏には文字コードの不一致が存在します。 「文字コードを理解する」ことは、正確なテキスト処理を行うための第一歩です。